|
|
You are here: Panda Wiki>Daq Web>WebHome (2014-10-28, MilanWagner)Edit Attach
Panda DAQ
PandaDaqArchitecture
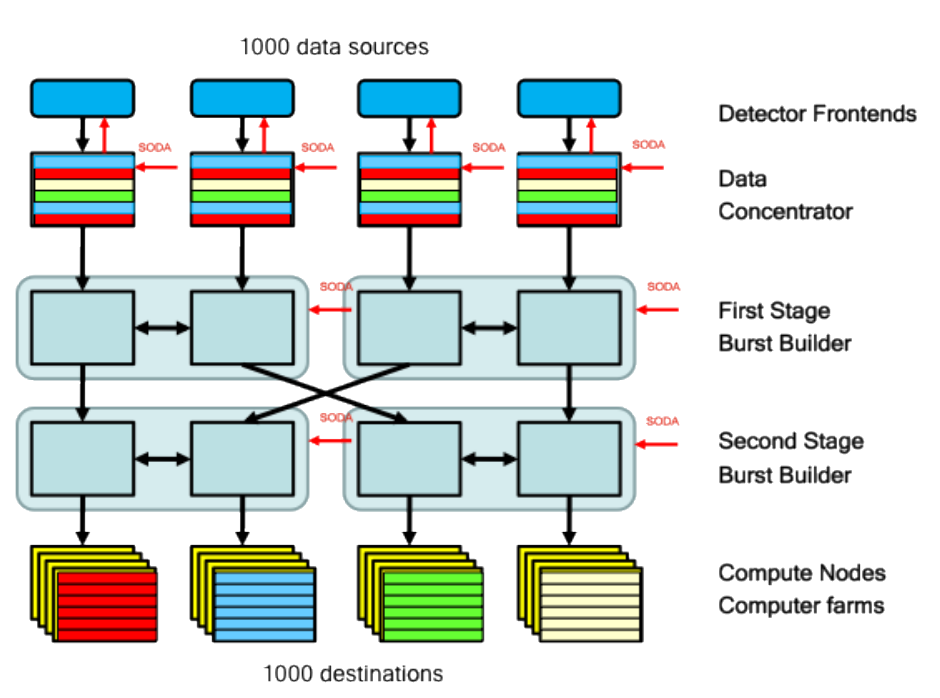
Operating in a free steaming mode, the PANDA DAQ (data acquisition) will be a system without any hardware trigger.As mentioned before the DAQ has to handle a high average interaction rate of 20 MHz with a peak up to 50 MHz and an event size of a few kilobyte. This leads to a data rate of several hundreds of GB/s. For efficient storing a reduction of the data rate by at least three orders of magnitude has to be fulfilled. This is feasible because many of the physics channels, which will be analysed at the PANDA experiment, have cross sections with several orders of magnitude lower than the cross section of the background. Therefore a intelligent data acquisition is needed. The reduction will be achieved by filtering the events online using informations of tracking, calorimetry and particle identification. The PANDA DAQ has to handle a very high average data rate of 2 · 10^7 Hz, with has to be reduced be at leased a factor of more than 1000. This will be achieved in a hierarchical way. The first part will be burst building, which is clustering and sorting the data, and the second stage will be reconstructing, entangling and filtering the data.
The PANDA DAQ has to handle a very high average data rate of 2 · 10^7 Hz, with has to be reduced be at leased a factor of more than 1000. This will be achieved in a hierarchical way. The first part will be burst building, which is clustering and sorting the data, and the second stage will be reconstructing, entangling and filtering the data.
Hardware
Data Concentrator
TRB
ComputeNode
An FPGA-based computational node for PANDA, BESIII and HADES. For information about old and deprecated versions of the Compute Node, please refer to this page.Compute Node Version 3 (CNv3):
Motherboard
The so called Compute Node (CN) is foreseen as the FPGA-based hardware component of the PANDA DAQ. The third revision of the CN is an ATCA (Advanced Telecommunications Computing Architecture) based carrier board. It is able to hold up to 4 xFP boards. The CN is equipped with a Xilinx Virtex 4 FX60 as a switching FPGA to connect the xFP boards in an intelligent way to the backplane. It also supplies direct high speed communications between these boards via Rocked IO.
Daughterboard (xFP)
An xFP board is an Extended Telecommunications Computing Architecture (xTCA) compliant board. It is an FPGA based μTCA compliant board featuring a Xilinx Virtex 5 FX70T -2 FPGA, 4 GB DDR2 RAM, 1Gb Ethernet, and 4 SFP+ (Small Form Factor Pluggable) cages. These cages can be equipped for example with optical or RJ45 interfaces.
A precise description of the xFP v3 boards is given by:
SODAnet
SoDA
SoDa is the previous version of SODAnet, pleas see: FEE Soda Specifications.Pre-AssemblyDAQ
Due to the fact that it is planned to have a functional pre-assembling of the PANDA detector at the Research centre Jülich, a prototype DAQ related to the PANDA DAQ has to be built. It will be a DAQ system with similar components and similar functionality as the final DAQ, but less requirement according to lower data rates in the pre-assembling phase. The pre-assembly DAQ will be realised in a three step process. As a first step the prototype trigger-less data acquisition (PTDAQ), a small but scalable start version, is prepared. It will be used for testing sub-detector prototype. Using the same online reconstruction algorithms as the PANDA DAQ, it will provide a full online event building. For testing reasons a SODANET emulator has be prepared. The second step will be an extended version including the CN. This allows a better interconnection between the xFP cards, and higher data rate handling. Starting with one CN, this version can than be expanded to the final pre-assembly DAQ.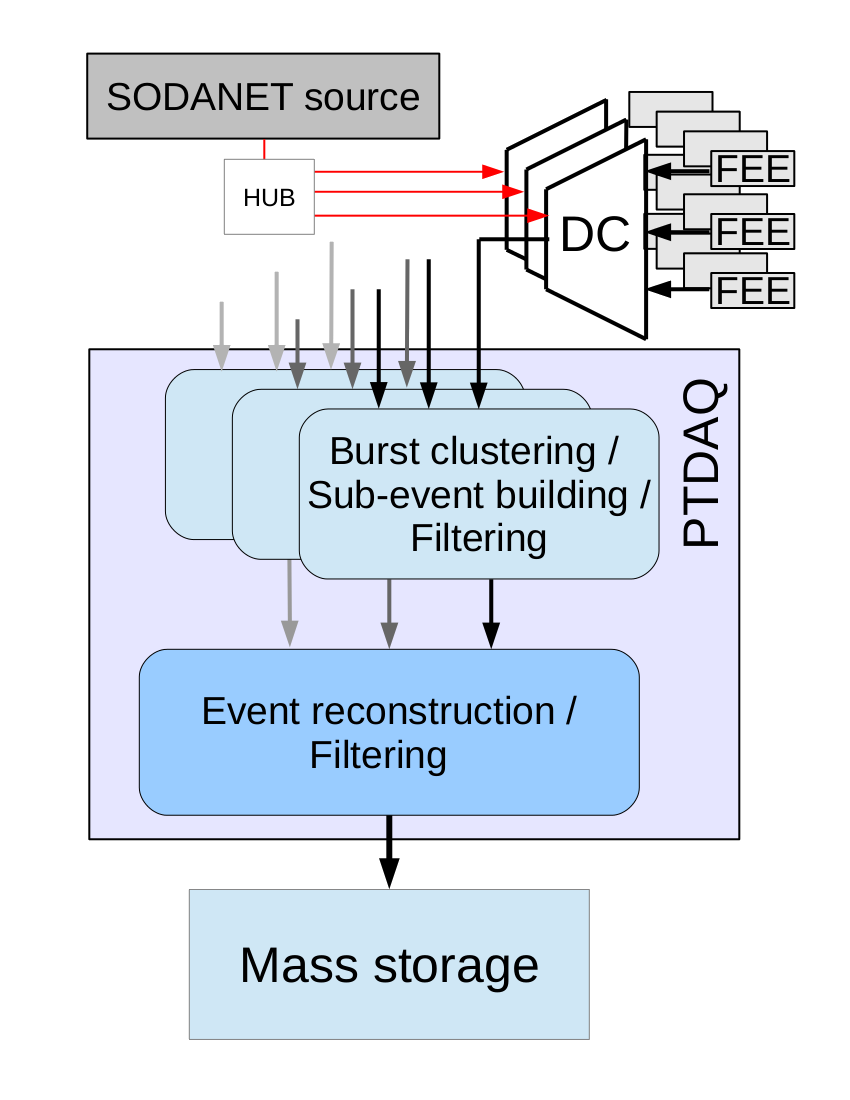
List of Presentations
These documents describe the concept and the status of the functional pre-assembly DAQ- File " pandameeting_10_09_13.pdf" contains description of the first concept.
- File " Panda_meeting_12_13.pdf" is an update and status report.
- File " boppard_talk.pdf" is a description how to increase the existing system to the final pre-assembly DAQ.
DataFormats
This page should list the modules (data concentrators) for each subdetector, including the data and format of the input and output data. Please edit this page accordingly.Hardware tests
Using PandaRoot simulation files there will be further tests on the CN's on the Feature Extraction level. First there will only be FTS and STT events used as converters for these are already written. The other detectors and their subsystems will follow. The used binary data format will look as follows till further specifications will be decided. The data values in the sub fragments will cover the given event data like x,y values for the STT. IDs like the straw numer will then be covered by the sub fragment ID and the detector ID will be inserted as fragment ID. It is foreseen, that the CN will process multiple of these packages from existing event files. So one can compare the feature extracted data with the present event files.
The data values in the sub fragments will cover the given event data like x,y values for the STT. IDs like the straw numer will then be covered by the sub fragment ID and the detector ID will be inserted as fragment ID. It is foreseen, that the CN will process multiple of these packages from existing event files. So one can compare the feature extracted data with the present event files.
ListOfMeetings
Material of DAQ meetings [Indico GSI]
Material of DAQ meetings [Indico Uni Giessen]
This is where you can find DAQ-related presentations of previous meetings.MeetingMinutes
Here we should upload all miscellaneous documentation like minutes of meeting, talks, posters and all kind of presentations/figures that could be interesting for future reference.Contacts / People Involved
*DAQ group coordinator*: WolfgangKuehn DAQ group co-cordinator: AngeloRivetti ZhenAnLiuIgorKonorov
AlexanderMann
BjoernSpruck
SoerenFleischer
MilanWagner
and others.
List of Pandadaq wikipages
- AdvancedTCA
- ComputeNode
- ComputeNodeLegacy
- Daq.Hardware
- KrakowMay2007
- ListOfMeetings
- MeetingMinutes
- MunichDecember2007
- PandaDaqArchitecture
- Daq.Pre-AssemblyDAQ
- Daq.SODAnet
- SoDA
- WebChanges
- WebHome
- WebIndex
- WebLeftBar
- WebNotify
- WebPreferences
- WebRss
- WebSearch
- WebSearchAdvanced
- WebStatistics
- WebTopicList
Site Tools of the Daq Web
No permission to view WebSiteTools Notes: No permission to view YouAreHere

| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
Dataformat.png | manage | 45 K | 2014-06-12 - 14:04 | ChristopherHahn | Dataformat for first level feature extraction tests |
| |
MAN-AM4901-IPMI.pdf | manage | 474 K | 2014-06-06 - 14:47 | UnknownUser | |
| |
MAN-AM4901.pdf | manage | 532 K | 2014-06-06 - 14:45 | UnknownUser | |
| |
MicroTCA_User’s_Manual.pdf | manage | 1 MB | 2014-06-06 - 14:50 | UnknownUser | |
| |
Panda_meeting_12_13.pdf | manage | 3 MB | 2014-06-06 - 14:55 | UnknownUser | |
| |
Slides--wagner-wagner.compute.pdf | manage | 3 MB | 2014-06-06 - 15:56 | UnknownUser | |
| |
boppard_talk.pdf | manage | 3 MB | 2014-06-06 - 14:57 | UnknownUser | |
| |
daq_trans.png | manage | 141 K | 2014-06-06 - 13:29 | UnknownUser | |
| |
pandameeting_10_09_13.pdf | manage | 3 MB | 2014-06-06 - 14:58 | UnknownUser |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r23 < r22 < r21 < r20 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r23 - 2014-10-28, MilanWagner
Daq Web
Web Home | Search Changes | Notifications Index | Topics
Web Home | Search Changes | Notifications Index | Topics
- Webs
- Cerenkov * Cerenkov.Pandacerenkov * DCS * Daq * Daq.Pandadaq * Detector * EMC * EMPAnalysis * Forwardstraws * GEM * MC * Magnet * Main * Mvd * PANDAMainz * PWA * Pbook * Personalpages * Physics * Physics.Baryons * Physics.CharmoniumAndExotics * Physics.HadronsInNuclei * Physics.OpenCharm * PhysicsCmt * SPC * STT * Sandbox * ScrutinyGroup * Tagpid * Tagpid.Pandatagpid * Tagtrk * Tagtrk.Pandatagtrk * Target * Target.ClusterJetTarget * Tof * WebServices * YoungScientists * ZArchives
Create personal sidebar
Copyright © by the contributing authors. All material on this collaboration platform is the property of the contributing authors.
Ideas, requests, problems regarding Panda Wiki Send feedback | Imprint | Privacy Policy (in German)
Ideas, requests, problems regarding Panda Wiki Send feedback | Imprint | Privacy Policy (in German)