|
|
You are here: Panda Wiki>DCS Web>PANDACSS (2013-02-19, FlorianFeldbauer)Edit Attach
CSS PANDA
This is the wiki of the PANDA-specific CSS versionOn this page database definitions for the archiver and alarm handler can also be found. I recommend to use PostgreSQL because it has much more features (e.g. table partitioning) and better performance than MySQL.
It is also possible to use Oracle.
Prerequisites
To use CSS-Panda you will need the following things:- Java JDK and JRE (at least version 6)
- JavaMessageServer (JMS) (e.g. Apache ActiveMQ)
- SQL database server (e.g. PostgreSQL, MySQL or Oracle)
Overview
CSS-PANDA consists of 5 individual applications:- AlarmConfigTool - Tool to configure the AlarmServer
- AlarmServer - Background process that scans all configured EPICS PVs for their alarm states
- ArchiveConfigTool - Tool to configure the ArchiveEngine
- ArchiveEngine - Background process that collects samples from EPICS PVs and stores them in a RDB
- css-panda - Graphical User interface including Databrowser to view archived data as strip chart, GUI for the alarm handler and operators interface (OPI) editor
AlarmConfigTool
Command-line tool for exporting alarm config as XML, or to import XML config into RDB. Can be used to generate snapshots of the configuration. To import 'foreign' formats like ALH, they can be converted into XML and then imported. Note that this this tool only interact with the alarm configuration in the RDB. After changing the configuration one should either restart the alarm server and GUI clients, or send the 'CONFIG' update message via JMS to trigger them to re-load the configuration.Basic Incantations
Note that alarm configurations are identified by their "Root" element. To specify RDB URL/user/password, add the option-rdb_url jdbc:... : default: 'jdbc:postgresql://localhost:5432/alarm' -rdb_user <user> : default: 'alarm' -rdb_password <password> : default: '$alarm' -rdb_schema <schema> : default: 'ALARM'
List Available Configurations
List all configurations, i.e. the names of all alarm tree 'root' elements currently found in the RDB:AlarmConfigTool <RDB settings> -list
Import Configuration
To import an initial configuration, or to replace the current configuration with root element "Test" with an XML snapshot, runAlarmConfigTool <RDB settings> -import -file /some/path/Test.xml -root TestThis deletes the configuration, then loads the file. The
-modify option will instead try to update the existing configuration,
i.e. load new components or PVs, or update the guidance etc. of existing
entries.
This would import the demo.xml:
AlarmConfigTool <RDB settings> -import -file /some/path/demo.xml -root demoNote that the name of the root element in the configuration file must match the name specified in the
-root .... command-line argument.
This is a basic consistency check to avoid importing the wrong configuration.
It is best to always specify the full path to the XML configuration file.
When not using the full path, the tool will read or create files relative
to its current working directory, which in turn will be the 'workspace'
directory that depends on the operating system and can thus be somewhat unpredictable.
Using the full, absolute path, there will be no surprises.
Export Configuration
To take an XML snapshot of the current configuration with root element "Test", runAlarmConfigTool <RDB settings> -export -file /some/path/Test.xml -root TestAgain provide the full path to the XML file to assert that it is indeed created in the desired location.
Edit Configuration
Export, edit the file, import again.Remove Configuration
Export, edit the file to remove all but the top-level "config" element, import again. This leaves the "root" element in the RDB. If desired, it needs to be removed manually via direct RDB SQL access like this:-- List all 'root' elements, note its NAME or COMPONENT_ID SELECT * FROM ALARM_TREE WHERE PARENT_CMPNT_ID is null; DELETE FROM ALARM_TREE WHERE NAME='that_name';
Copy Configuration
To create a new configuration "CopyOfTest", first export "Test", then edit the root "config" element in the configuration file to be "CopyOfTest", and finally import that edited file as "CopyOfTest". The editing is required because the tool will only import configuration files into the root that matches the top level element in the file. This is a simple consistency check.Alarm Configuration Syntax
A minimal, empty configuration with the root element demo would look like this:<config name="demo"> </config>For a better overview in the alarm system user interface the monitored PVs can be arranged in components (groups).
<component name="SomeGroup">
<!-- List of PVs -->
</component>
<component name="AnotherGroup">
<!-- List of PVs -->
</component>
The alarm system will typically latch alarms. This means that the alarm trigger PV can return to OK, later
re-enter the alarm state and so on, but the alarm system will only react when a PV enters an alarm state
for the first time. Subsequently, the alarm system user interface will display the current state of the PV,
but it will not trigger a new alarm nor issue another annunciation. This is meant to reduce noise from the
alarm system.With the
latching statement in the config file this behaviour can be changed for each PV.
<pv name="SomePVname">
<description>PVdescription</description>
<latching>true</latching>
<annunciating>true</annunciating>
</pv>
A complete configuration file is included in the package (css-panda/AlarmConfigTool/demo.xml)
AlarmServer
The Alarm Server reads an alarm configuration, monitors the PVs of that configuration and notifies alarm clients about changes in the alarm state. It persists the alarm state in the RDB. For example, information about latched alarms is written to the RDB. When the Alarm Server is stopped and re-started, it will initialize from the RDB and learn about the previous state of all alarms. This way a previously latched alarm is recognized and not reported as a new alarm.Configuration
The Alarm Server is a command-line tool that is configured via Eclipse preferences. These preferences are stored in the filecss-panda/AlarmServer/settings.ini:
# Generic Alarm Server Settings # Alarm System 'root', i.e. configuration name org.csstudio.alarm.beast/root_component=Annunciator # Alarm System RDB Connection org.csstudio.alarm.beast/rdb_url=jdbc:postgresql://localhost:5432/alarm org.csstudio.alarm.beast/rdb_user=alarm org.csstudio.alarm.beast/rdb_password=$alarm org.csstudio.alarm.beast/rdb_schema=ALARM # Alarm System JMS Connection org.csstudio.alarm.beast/jms_url=failover:(tcp://localhost:61616) org.csstudio.alarm.beast/jms_user=alarm org.csstudio.alarm.beast/jms_password=$alarm # Alarm Server: Period for repeated annunciation of active alarms org.csstudio.alarm.beast.server/nag_period=00:15:00 # Channel Access # Network traffic can be optimized by only monitoring ALARM updates org.csstudio.platform.libs.epics/use_pure_java=true org.csstudio.platform.libs.epics/support_dbe_property=true org.csstudio.platform.libs.epics/monitor=ALARM org.csstudio.platform.libs.epics/addr_list= org.csstudio.platform.libs.epics/auto_addr_list=true # Logging preferences org.csstudio.logging/console_level=CONFIG org.csstudio.logging/jms_url= org.eclipse.ui/SHOW_PROGRESS_ON_STARTUP = falseThe RDB and JMS Connection settings have to match the configuration of environmental set up. Note that in contrary to the command-line argument from the config tool the RDB schema must not end with '.' in the settings.ini file. If the AlarmServer is running on a machine with multiple active network connections the channel access protocol will find the PVs existing on this host at all IP addresses which will cause an error because PV names must be unique within the whole network. In this case set
auto_addr_list=false and list all relevant IP addresses for channel access in addr_list seperated by a single blank.
To start/stop the AlarmServer a shell script is included (css-panda/AlarmServer/alarmserver). The DIR variable in this
file must be set to the path where the AlarmServer is located.
ArchiveConfigTool
Command-line tool for exporting archive config as XML, or to import XML config into RDB. Can be used to generate snapshots of the configuration.Basic Incantations
Note that archive configurations are identified by their "Engine". To specify RDB URL/user/password, add the option-rdb_url jdbc:... : default: 'jdbc:postgresql://localhost:5432/archive' -rdb_user <user> : default: 'archive' -rdb_password <password> : default: '$archive' -rdb_schema <schema> : default: 'archive'
List Available Configurations
List all archive engines currently found in the RDB:ArchiveConfigTool <RDB settings> -list
Import Configuration
To import an initial configuration, or to replace the current configuration of an engine named "Test", runArchiveConfigTool <RDB settings> -import -config /some/path/Test.xml -engine Test -description "Description of this engine" -host localhost -port 4812 [-replace_engine]The ArchiveEngine uses a web interface to display status information. The address is defined with the
-host and -port arguments. Typically localhost and port 4812 are used.
Each channel can only be used in one engine. If setting up a second engine with channels that are already in another engine append the argument -steal_channels.
This overwrites the engine settings for all channels in the imported configuration that are already in another engine.
It is best to always specify the full path to the XML configuration file.
When not using the full path, the tool will read or create files relative
to its current working directory, which in turn will be the 'workspace'
directory that depends on the operating system and can thus be somewhat unpredictable.
Using the full, absolute path, there will be no surprises.
Export Configuration
To take an XML snapshot of the current configuration of an engine runArchiveConfigTool <RDB settings> -export -config /some/path/Test.xml -engine TestAgain provide the full path to the XML file to assert that it is indeed created in the desired location.
Edit Configuration
Export, edit the file, import again using-replace_engine.
Remove Configuration
ArchiveConfigTool <RDB settings> -delete_config -engine TestThis deletes only the entry in the engine table. The channels and samples stay in the RDB. If desired, the channels and samples need to be removed manually via direct RDB SQL access.
Sample Modes
The archive engine supports several sample modes, i.e. ways in which it decides what samples should be written to the archive data store.Monitored
In monitored mode, each received sample is written to the store. With a perfectly configured data source, for example an EPICS ADEL that only passes significant changes to the archive engine, this mode is ideal: Significant changes in value are written to the archive, while noise in the signal is suppressed to minimize wasted resources. When configuring a monitored channel, the estimated time period between changes needs to be configured to allow the archive engine to reserve a suitable memory buffer where it stores received samples until they are written to the storage.Monitored With Threshold
This mode is also monitored, but adding another value change threshold filter. Ideally, the front-end computer already performs the thresholding, so only significant changes are sent over the network to the archive engine. In some cases, however, this is not possible, and for those cases the archive engine itself can check for changes in the value, writing only samples that differ from the last written sample by at least some configurable margin. As with plain monitored channels, the estimated time period between changes needs to be configured.Scanned/Sampled
In scanned mode, the archive engine still receives each update from the data source, but it only writes the most recent sample at periodic times, for example once every 5 minutes. For a scanned channel you configure the period at which the archive engine should check the channel for its current value. This mode is a compromise. If a channel has no significant change for hours, why should the uninteresting changes fill disk space every 5 minutes? On the other hand, if an important even happens that produces a brief blip in the data, the archived data is likely to miss it when only storing a value every 5 minutes. This mode was created for channels which do not have a good dead-band configuration, where using the monitored mode would add too many samples to the archive. Periodic sampling is clearly imperfect, but sometimes a workable compromise.Archive Configuration Syntax
The Syntax for the configuration file is explained in the demo configuration (css-panda/ArchiveConfigTool/demo.xml)
ArchiveEngine
The ArchiveEngine is a headless RCP application that reads a sample engine configuration, connects to the control system channels listed in the configuration, and writes received samples to the archive data store. Samples obtained by the various samples modes are not immediately written to storage, for example the RDB, because writing each individual sample right away would be too slow. Instead, samples are initially kept in memory, then written to storage in bulk. By default, this write period is 30 seconds.Built-in Web Server
Each sample engine has a built-in web server for status information and basic remote control of the engine. When starting the engine on a host, the port number for this HTTPD must be provided. The sample engine URL configured in the RDB should match the formathttp://<host>:<port>/main
The engine will compare the port number from the URL with the port number provided as a commandline
argument.
The engine web server provides several web pages, mostly linked from the .../main URL, that allow
you to see: - Is the engine running? Since when?
- Are all channels connected? Which are disconnected?
- What is the last data that a channel has received? What is the last sample that was written to the storage?
http://localhost:4812
will result in an empty page. You have to start browsing at http://localhost:4812/main.
Starting at .../main, one can drill down to the status of groups and individual channels.
A few engine web pages are not accessible by following web browser links because they affect the engine
operation. This is meant to prevent a web-crawling program to accidentally stop the engine.
http://<host>:<port>/stop |
Invoke this URL to stop the engine gracefully, i.e. to ask the engine to write a final Archive_Off sample to each channel, then quit. |
http://<host>:<port>/restart |
Invoke this URL to trigger a running restart of the engine. The engine will stop sampling, read its configuration, then start again. Invoking this URL is required after changes to the configuration of an archive engine. |
http://<host>:<port>/reset |
Invoke this URL to reset engine statistics, for example the average write time displayed on the main page of the engine. |
http://<host>:<port>/environment |
Invoke this URL to display engine environment settings which might be useful when trying to debug a problem. |
Configuration
Like the AlarmServer the ArchiveEngine is configured via Eclipse preferences which are stored in the filecss-panda/ArchiveEngine/settings.ini.
Again the RDB Connection settings (and in some cases the Channel Access settings)
have to match the configuration of environmental set up.
For starting the Engine the shell script css-panda/ArchiveEngine/archiveengine can be used.
Stopping the engine using this script is not recommended because it will lead to data loss due
to the sample storage routine. http://<host>:<port>/stop should be invoked instead.
css-panda
This is the main part of the package. It contains the graphical user interface for EPICS and the Alarm Handler. In principal CSS is an Eclipse IDE. To edit or create operators interfaces (OPIs) for an underlying EPICS control system the perspective "OPI Editor" is used. For using the OPI to interact with the control system the "OPI Runtime" perspective is used. By default CSS-PANDA looks for its workspace always in the directory from where it is started! This behaviour can be changed with the-data command line argument
css-panda -data /path/to/workspaceIt is best to use always the workspace already existing in this package (
css-panda/css-panda/workspace ), because color and font definitions used by the OPI builder
reside in this directory.
Tools
In addition to the OPI Builder CSS provides lots of tools like the Data Browser, a GUI for the Alarm System, accessing a logbook directly from within CSS (with attached snapshots), sending emails via a smtp server, authentication, and authorization (via Kerberos, LDAP, ...). Currently CSS-PANDA uses a dummy authentication and authorization, which means every username and password will be accepted. As logbook the Midas logbook from PSI is used.OPI Builder
The OPI Editor provides lots of widgets. For each widget one can define multiple rules which e.g. allows to make values of different properties dependent on PV values and therefore dynamic. Also it is possible to extend the functionality of the OPIs with Javascript or Python Script. Like EPICS CSS allows macros in text based properties like PV names, tooltips, and rules. These macros are replaced at runtime with the appropriate values. The macros using the format$(macro_name) or ${macro_name}.
Data Browser
Another tool provided by CSS is the Data Browser. This is a trending tool, which can display the values of PVs and plots them over time. The values are collected as 'live' samples from the control system as well as archived data samples from the ArchiveEngine RDB. It is possible to make a logbook entry with a snapshot of the current stirpchart attached from the context menu of the Data Browser.Configuration
The configuration of CSS-PANDA can be done in two ways: Using a settings.ini file like for the ArchiveEngine and AlarmServer which is loaded with the command-line argument-pluginCustomization /path/to/settings.ini
or using the preference gui inside CSS (Edit->Preferences).
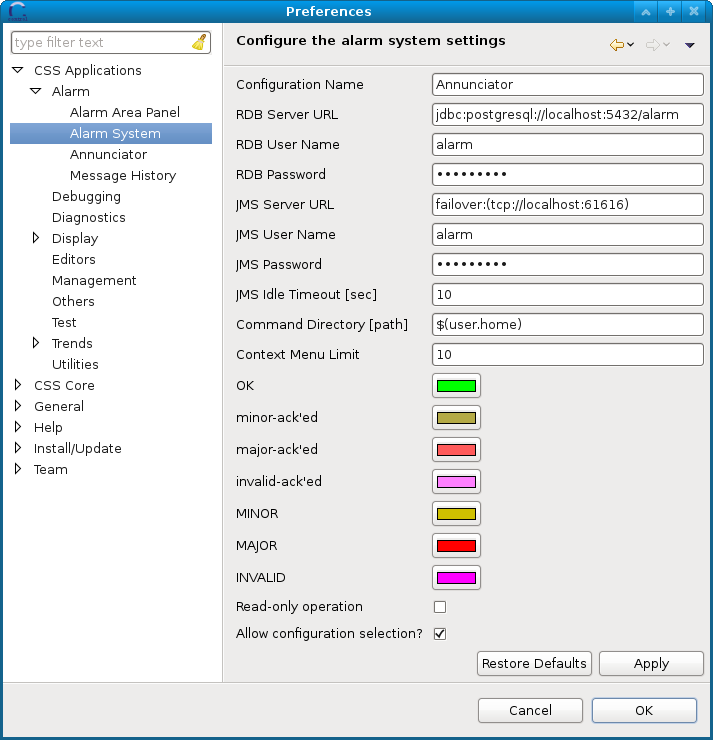
- Preferences GUI for Alarm System:
Edit | Attach | Print version | History: r11 < r10 < r9 < r8 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r11 - 2013-02-19, FlorianFeldbauer
DCS Web
Web Home | Search Changes | Notifications Index | Topics
Web Home | Search Changes | Notifications Index | Topics
- Webs
- Cerenkov * Cerenkov.Pandacerenkov * DCS * Daq * Daq.Pandadaq * Detector * EMC * EMPAnalysis * Forwardstraws * GEM * MC * Magnet * Main * Mvd * PANDAMainz * PWA * Pbook * Personalpages * Physics * Physics.Baryons * Physics.CharmoniumAndExotics * Physics.HadronsInNuclei * Physics.OpenCharm * PhysicsCmt * SPC * STT * Sandbox * ScrutinyGroup * Tagpid * Tagpid.Pandatagpid * Tagtrk * Tagtrk.Pandatagtrk * Target * Target.ClusterJetTarget * Tof * WebServices * YoungScientists * ZArchives
Create personal sidebar
Copyright © by the contributing authors. All material on this collaboration platform is the property of the contributing authors.
Ideas, requests, problems regarding Panda Wiki Send feedback | Imprint | Privacy Policy (in German)
Ideas, requests, problems regarding Panda Wiki Send feedback | Imprint | Privacy Policy (in German)